
A tax team was selecting investment vehicles from 2000+ SPVs using Excel and email. I designed an AI recommendation system within an enterprise platform — then navigated a mid-project platform change, a trust problem with AI outputs, and a scope decision that broke the user's workflow.
A tax team at a global investment firm had to select SPVs — Special Purpose Vehicles — for every private market deal. There were over 2000 of them. The whole process ran on Excel and email. No audit trail. No standardised criteria. No way to go back six months later and trace why a particular SPV was picked for a particular deal.
The deeper issue was structural. The deal team — the people who were out there getting deals — weren't on the platform at all. The tax team's work was entirely downstream of a team operating in a different system. Anything we built had a ceiling because of that gap.
We ran interviews across three regions — America, Europe, and Asia. These teams had different processes, different regulatory contexts and different relationships with their deal teams. We also ran a POC to test the AI recommendation logic with users before committing to a full build.
One thing a user said during the POC stuck with us: "All I need to do is add a new line in Excel." That became the bar. If what we built felt like more work than a spreadsheet, people would go back to their spreadsheets.
Midway through, the platform direction changed. We'd been building something purpose-built. The decision came down to integrate into the existing mid-office platform instead.
Users who'd seen the POC showed up expecting something close to that experience — clean, dedicated, AI front and centre. What they got looked and felt different. The POC was built to show what was possible. The integration was built within the constraints of a platform that wasn't designed for this.

Looking back, I should've flagged the expectation gap earlier as a design risk. I treated it as a comms problem for the PO to handle. It was actually a design problem — the shift from POC to production needed its own thinking, not just a change log.
The platform had a constraint: a workflow task had to exist before a deal could be logged. Technical requirement, not user-driven. Users showed up wanting to log a deal. The system told them to create a task first.
The BA, PM, and I all agreed it should be the other way around — log the deal, let the system handle the task behind the scenes. My design lead went with the constraint. We shipped it that way.
Users gave feedback that the friction was too high. They'd rather use Excel. The decision got reversed. Engineering built an API to handle task creation invisibly, and the flow was updated to what we'd recommended in the first place.
What I took from that: the argument was sound and everyone knew it. What was missing was a trade-off document that laid out user impact, dev cost, and risk in a format the decision-maker could act on. I didn't shape the case for the person who had to say yes.
The challenge wasn't the AI. It was getting domain experts to trust the output enough to act on it.
Users pushed back early. A percentage match on its own wasn't enough. They wanted to understand why one SPV ranked higher than another. Without that, they'd just ignore the percentage and go check their spreadsheet.
So every SPV card showed a plain language justification alongside the score. Not tucked away — the justification was the main thing. The card also surfaced the fields users said they needed to verify a recommendation: country of incorporation, legal entity type, SPV type, holding company structure, ring-fenced status, bank account availability. They could click through to the full record for deeper due diligence.
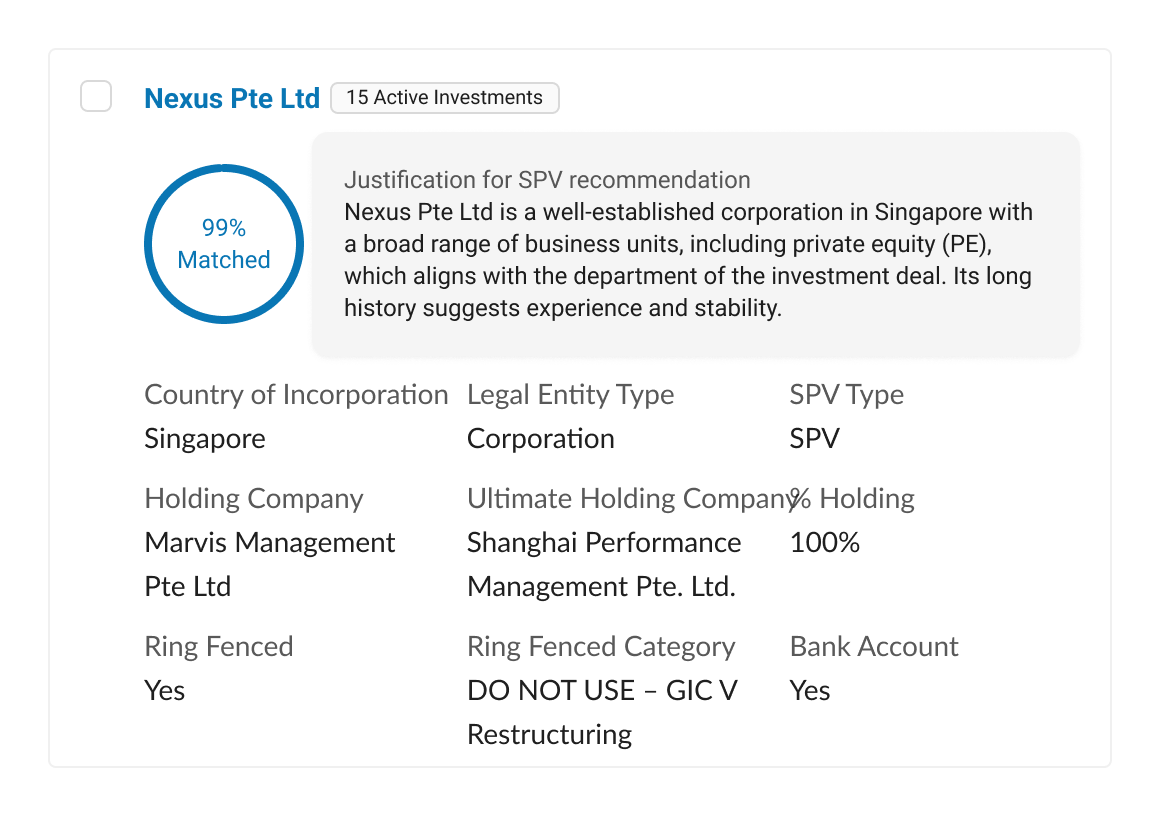
The pre-selected state reflected the AI's confidence ranking, but users could switch to manual selection. There were no automated decisions. In a compliance domain, a named person owns every selection.
One thing I didn't do and should have: formally test whether users actually trusted the AI or could spot wrong recommendations. The POC gave us some observational signal — people were reading the justifications and checking fields. But that was a small sample under observed conditions. In compliance, that gap matters.
MVP 1 had two modes: AI recommendation and manual selection, split across two tabs. Separating them kept the build manageable and got the feature out.
What it didn't cover was users who needed both. Some investments required multiple SPVs. Someone might use the AI for the first pick, then need to add another manually. There was no way to do that. They had to leave the AI tab, go to manual, and start over.
That was a real problem. The AI was useful right up until it wasn't, and the fallback felt like starting from scratch. The tab structure I'd picked was the cause. Two separate paths with no way to cross between them.
The fix — a combined flow where AI recommendations come first and users can add manual picks in the same view — was scoped for MVP 2.
Because the deal team wasn't on the platform, duplicates kept showing up. Two users could get tagged on the same deal independently. We built a reconciliation feature, but it had real gaps. There was no automated detection or rollback. It was user-initiated only.
The safeguards it actually needed — duplicate detection at point of entry, merge conflict handling, audit trail — were documented but not built. It shipped incomplete. I'm mentioning it because it's worth being upfront about the distance between what shipped and what the feature needed to be.
I'd do three things differently.
Flag design risks that aren't about the UI. The POC expectation gap was a design risk. The task-before-deal constraint was a design risk. I treated both as someone else's problem. They were mine to frame.
Build the trade-off document. When your recommendation gets overruled, the issue usually isn't the argument. It's the format. A one-pager showing user impact alongside dev cost alongside risk gives the decision-maker something concrete. I didn't do that, and the decision went the wrong way until users forced it back.
Test for trust, not just usability. In a domain where AI outputs have compliance implications, "users seemed to read the justifications" isn't enough. A structured test of whether people could catch wrong recommendations would've been worth doing.